
Автоматизация регламентной отчетности: экспорт данных из PolyAnalyst в шаблоны Excel и Word Системы PolyAnalyst и PolyAnalyst Grid предоставляют мощные инструменты...
Читать далееЧто такое Таксономия «Точно в Срок»?
Сегодня важный день. Возможно, вы только что выпустили на рынок новый продукт или услугу. Возможно, сегодня были опубликованы результаты опроса клиентов. Десятки тысяч комментариев, вопросов, отзывов, заявок в службу поддержки или каких-то еще текстовых документов заполонили вашу систему, и вашей команде необходимо всё это как можно скорее осмыслить и выявить ключевые паттерны и тренды, чтобы успеть эффективно использовать окно возможностей для принятия верных бизнес-решений. Но для этого кто-то должен структурировать полученный массив документов и перевести его в поддающуюся осмыслению форму. Эта задача решается путем выявления иерархической системы категорий, называемой таксономией, которая помогает структурировать основные темы, встреченные в массиве документов.
Используя традиционные методы, команде из нескольких аналитиков может потребоваться 3–4 недели на таксономизацию данных. За это время выявленные проблемы уже перезреют, возможности будут упущены, а критически важное окно для быстрого реагирования закроется. Конечно, вы можете использовать ранее заготовленную таксономию, но она будет охватывать только те категории, которые вы смогли предвидеть заранее.
Основанная на применении искусственного интеллекта (ИИ) технология Таксономия «Точно в Срок» (ТВС-таксономия) решает эту проблему. Вместо того, чтобы тратить недели на ручное создание категорий или пытаться рассортировать новые данные по заранее выбранным категориям, вам будет достаточно нажать кнопку «Старт», и пара ИИ-агентов проанализирует ваши данные и создаст новую пользовательскую таксономию менее чем за час. ТВС-таксономия, созданная на основе семантического анализа ваших данных прямо в день их получения, позволяет оперативно выявить все важные темы (категории), в том числе ранее неизвестные, и провести классификацию документов по этим категориям.
Но как это работает? И когда имеет смысл использовать этот подход вместо традиционных методов?
Как это работает: система из двух агентов
Решение, реализующее таксономию «Точно в Срок», использует двух специализированных агентов ИИ, которые работают совместно для анализа пользовательских данных.
Агент Создания Категорий (Конструктор Категорий) отвечает за выявление категорий, фактически присутствующих в ваших данных на основе их семантического анализа. Этот агент работает в три этапа: сначала он считывает ваш контент и генерирует потенциальные метки для найденных тем. Например, если ваши данные представляют собой отзывы клиентов о мобильном приложении, агент может определить потенциальные метки, такие как «разряд батареи», «проблемы со входом», «медленная загрузка», «запутанная навигация», «сбои при запуске», «отличный дизайн», «хорошая техподдержка» и десятки других, последовательно обрабатывая каждый отзыв.
Конструктор Категорий представляет собой трехэтапный конвейер.
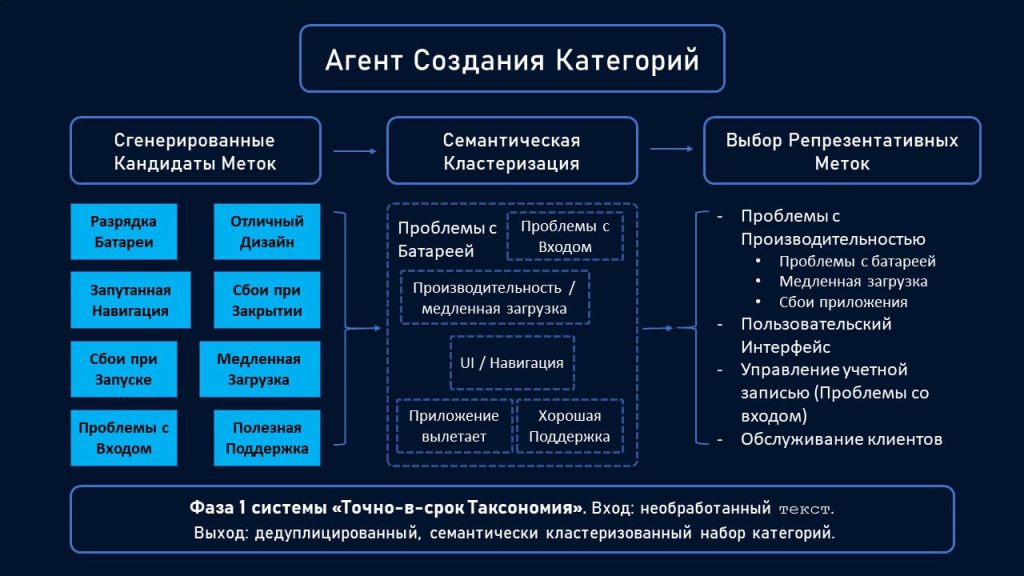
На втором этапе агент группирует эти потенциальные метки посредством семантической кластеризации. Он распознаёт, когда разные метки обозначают одно и то же понятие. Например, если клиенты упоминали «время работы аккумулятора», «разряд аккумулятора» и «низкая производительность аккумулятора», они будут объединены в один кластер, поскольку все они говорят об одной и той же проблеме, используя разные слова. Аналогично, «сложности со входом в систему», «проблемы со входом в систему» и «невозможно войти в систему» будут объединены в один кластер, в то время как «сбои», «сбои приложения» и «зависания» могут образовать другой кластер.
Наконец, на третьем этапе агент выбирает наиболее репрезентативную метку для каждого кластера. В кластере, связанном с аккумулятором, он может выбрать «Проблемы с аккумулятором» как наиболее общую и понятную метку. В кластере, связанном с входом в систему, он может выбрать «Проблемы со входом в систему» как наиболее понятный термин.
Этот процесс устраняет избыточность категорий и создает «чистую» таксономию, где каждая категория представляет отдельную концепцию, даже если клиенты описывают ее разными способами.
Агент Тегирования Документов принимает на вход отдельные документы и соотносит их с соответствующими категориями из таксономии, созданной Агентом Создания Категорий. Его можно рассматривать как агента, который фактически выполняет работу по организации данных после того, как категории созданы.
Агент Тегирования Документов сопоставляет документы с категориями, обнаруженными Агентом Создания Категорий.
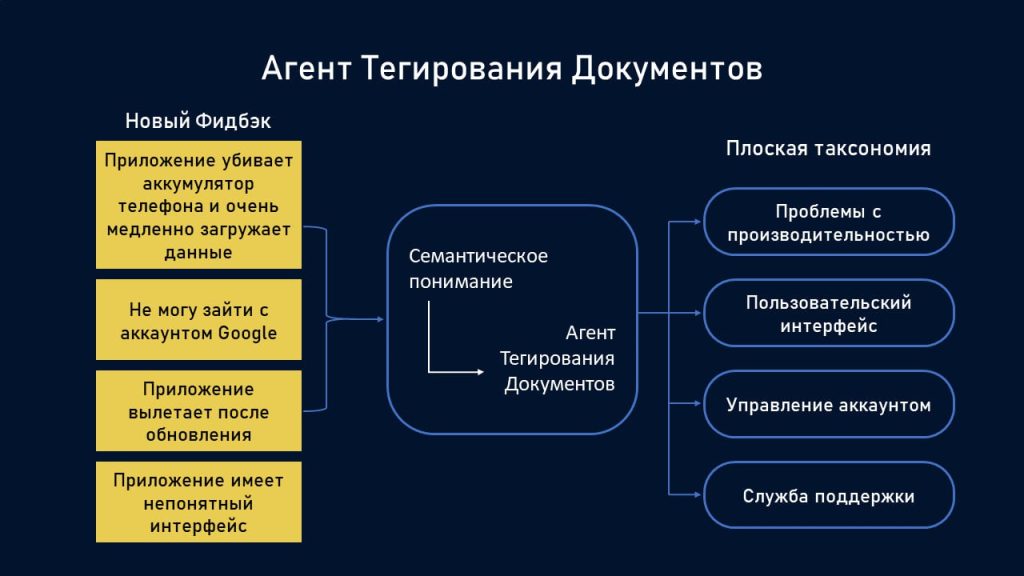
Когда на вход поступает новый отзыв, например, клиент пишет: «Это приложение убивает аккумулятор моего телефона и очень медленно загружает данные», — Агент Тегирования Документов считывает его и определяет применимые категории. В данном случае он, скорее всего, пометит этот отзыв как «Проблемы с аккумулятором», а также какой-то категорией, выбранной системой для обозначения проблем с загрузкой или производительностью.
Агент Тегирования Документов ищет не только точные совпадения по ключевым словам. Он понимает смысл и контекст документа. Поэтому, если кто-то пишет: «Мой телефон очень быстро разряжается, когда я использую это приложение», агент распознаёт проблему с аккумулятором, несмотря на то что слово «аккумулятор» в этом документе не использовалось. Аналогично, фраза «Приложение работает со скоростью черепахи» будет помечена тегом проблем с производительностью, несмотря на то что слова «скорость черепахи» отсутствовали в исходных тегах-кандидатах.
Этот агент может обрабатывать контент по мере его поступления, оперативно классифицируя новые отзывы, запросы в службу поддержки или ответы на опросы, используя таксономию, сформированную на основе вашего исходного набора данных. Он также может обрабатывать случаи, когда один и тот же фрагмент контента относится сразу к нескольким категориям, как в нашем примере выше, где были затронуты проблемы как с аккумулятором, так и с производительностью.
В результате ваши данные упорядочиваются в режиме реального времени, причем каждый новый документ автоматически сортируется по категориям, которые имеют смысл для вашей конкретной ситуации.
Создание синергии: сотрудничество агентов
Когда на вход поступает новый отзыв, например, клиент пишет: «Это приложение убивает аккумулятор моего телефона и очень медленно загружает данные», — Агент Тегирования Документов считывает его и определяет применимые категории. В данном случае он, скорее всего, пометит этот отзыв как «Проблемы с аккумулятором», а также какой-то категорией, выбранной системой для обозначения проблем с загрузкой или производительностью.
Агент Тегирования Документов ищет не только точные совпадения по ключевым словам. Он понимает смысл и контекст документа. Поэтому, если кто-то пишет: «Мой телефон очень быстро разряжается, когда я использую это приложение», агент распознаёт проблему с аккумулятором, несмотря на то что слово «аккумулятор» в этом документе не использовалось. Аналогично, фраза «Приложение работает со скоростью черепахи» будет помечена тегом проблем с производительностью, несмотря на то что слова «скорость черепахи» отсутствовали в исходных тегах-кандидатах.
Этот агент может обрабатывать контент по мере его поступления, оперативно классифицируя новые отзывы, запросы в службу поддержки или ответы на опросы, используя таксономию, сформированную на основе вашего исходного набора данных. Он также может обрабатывать случаи, когда один и тот же фрагмент контента относится сразу к нескольким категориям, как в нашем примере выше, где были затронуты проблемы как с аккумулятором, так и с производительностью.
В результате ваши данные упорядочиваются в режиме реального времени, причем каждый новый документ автоматически сортируется по категориям, которые имеют смысл для вашей конкретной ситуации.
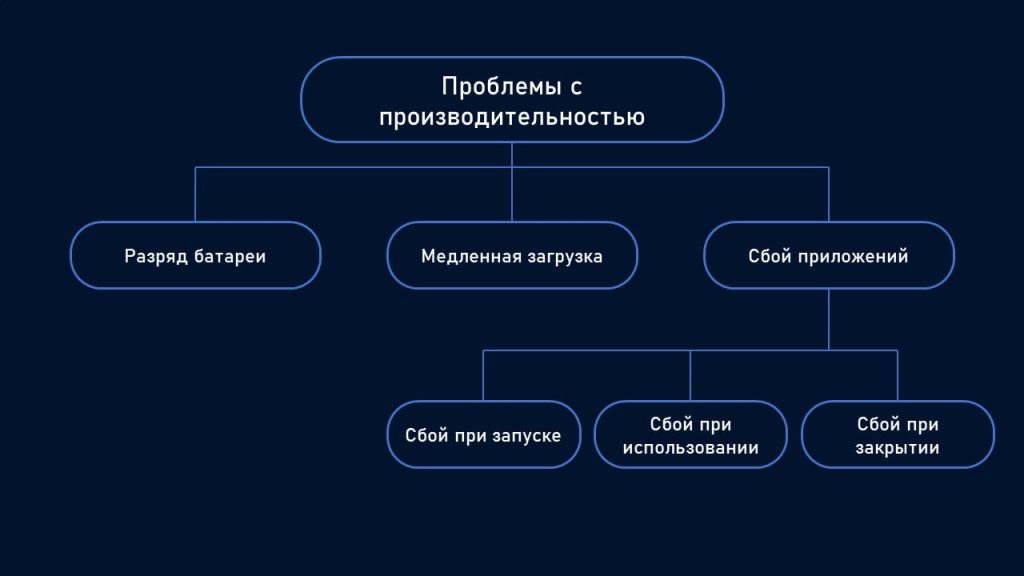
Фрагмент трехуровневой таксономии.
Реальная мощь этого подхода проявляется, когда описанные выше агенты работают в связке друг с другом в замкнутом цикле для создания многоуровневых таксономий, выявляющих как общие темы, так и специфические детали.
Продолжим наш пример с мобильным приложением. В ходе начального трёхэтапного процесса Конструктор Категорий создает общие категории верхнего уровня, такие как «Проблемы с производительностью», «Пользовательский интерфейс», «Управление учётными записями» и «Обслуживание клиентов». Затем Тегировщик Документов начинает классифицировать отзывы, используя эти общие категории.
Но по мере того, как Тегировщик Документов обрабатывает всё больше контента, он передаёт информацию о дополнительно выявленных закономерностях в Конструктор Категорий. В результате, Конструктор Категорий может заметить, что тег «Проблемы производительности» появляется очень часто и содержит чёткие подтемы. В этом случае он запускает ещё один этап анализа, на этот раз уделяя особое внимание отзывам с тегом «Проблемы производительности».
Благодаря этому целенаправленному анализу он обнаруживает, что проблемы производительности на самом деле делятся на более специфичные категории: «Разряд батареи», «Медленная загрузка», «Сбои приложений». Тогда Конструктор Категорий создаёт второй уровень иерархии, где «Проблемы с производительностью» являются родительской категорией, а перечисленные специфичные категории — ее подкатегориями.
Теперь Тегировщик Документов может работать с этой расширенной структурой. Когда поступает новый отзыв типа «Приложение сегодня трижды зависало и полностью разрядило мою батарею», агент может пометить его категориями нескольких уровней: в общей категории «Проблемы с производительностью» и в отдельных подкатегориях «Сбои приложения» и «Разряд батареи».
Этот процесс совместного анализа может продолжаться рекурсивно. Например, если количество сбоев приложения становится слишком большим, агенты могут обнаружить, что оно подразделяется на «сбои при запуске», «сбои во время использования» и «сбои при закрытии». Таким образом, таксономия может становиться сложнее по мере поступления новых данных, всегда оставаясь при этом основанной на темах, которые действительно присутствуют в ваших данных.
Примеры использования помимо мониторинга запуска продукта
Хотя обратная связь по запуску нового продукта является убедительным примером, Таксономии «Точно в Срок» решают задачи выявления скрытой структуры в больших массивах данных, возникающих при анализе различных типов неструктурированных текстовых данных.
Анализ опросов представляет собой одно из самых перспективных приложений технологии Таксономия «Точно в Срок». Ответы на открытые опросы часто содержат самую ценную информацию, но их также сложнее всего анализировать в больших масштабах. Традиционные подходы требуют прочтения аналитиком сотен или тысяч ответов для выявления тем, а затем кодирования каждого ответа вручную. При использовании ТВС-таксономии, агенты автоматически выявляют темы, присутствующие в ответах клиентов или сотрудников, и классифицируют их соответствующим образом. Что ещё важнее, эта технология позволяет вам увидеть полное распределение ответов — не только сводную статистику, но и то, как ответы группируются вокруг разных тем, и как выглядит полный спектр настроений в каждой категории.
Мониторинг данных социальных сетей становится доступным в новых, ранее невиданных масштабах. Благодаря автоматической генерации таксономий вы можете одновременно отслеживать тысячи инфлюенсеров, аккаунтов в социальных сетях и онлайн-общений. Традиционный подход к мониторингу социальных сетей требует предварительного задания тем и ключевых слов для отслеживания, что автоматически означает пропуск неожиданных обсуждений и новых тем. С помощью технологии ТВС-таксономии вы можете охватить всю экосистему своей отрасли и позволить системе узнать, о чём на самом деле говорят люди, включая вновь возникшие темы, которые вы и не предполагали отслеживать.
Программы сбора «голоса клиента» (Voice of the Customer, сокр. VoC) генерируют огромное количество неструктурированных данных обратной связи, поступающих из множества каналов общения с клиентами: упоминаний в социальных сетях, сайтов с отзывами, отзывов по электронной почте, фокус-групп и интервью с клиентами. Для каждой из них может быть создана своя собственная таксономия, или же может быть создана одна монолитная таксономия, объединяющая все эти различные источники данных в рамках единой иерархической структуры.
Анализ обращений в службу поддержки — ещё одна область успешного применения технологии ТВС-таксономий. Заявки в службу поддержки, журналы чатов и расшифровки звонков содержат ценную информацию о повторяющихся проблемах, но эта информация часто так и остаётся скрытой в рамках отдельных разговоров. Автоматически классифицируя обращения в службу поддержки, организация может быстро выявлять системные проблемы, понимать, какие проблемы требуют больших ресурсов для их разрешения, отслеживать закономерности для облегчения решения подобных проблем в будущем.
Объединяющей чертой всех этих приложений является одна и та же фундаментальная задача: у вас есть большие объёмы текста, которые необходимо разметить, структурировать и сделать доступными для поиска, чтобы выявить закономерности и получить ценную информацию. Будь то понимание причин обращения клиентов в службу поддержки, обнаружение неожиданных тем в данных опросов или отслеживание мнений по нескольким каналам обратной связи, Таксономии “Точно в Срок” преобразуют неструктурированный текст в упорядоченные, пригодные для анализа данные.
Расширение таксономии: поиск факторов, влияющих на ключевые показатели эффективности (KPI)
Создание таксономии может быть лишь первым шагом в разработке более масштабного бизнес-решения. Следующий шаг — расширение таксономии путём расчёта «показателей важности», которые показывают, какие категории действительно важны для эффективности вашего бизнеса. Мы делаем это, используя таксономические категории в качестве предикторов ключевого показателя эффективности, например, уровня удовлетворенности клиентов в данных опросов или рейтингов качества поддержки в ходе общения с клиентами. Самые сильные предикторы — это важнейшие факторы вашего KPI. Если эти показатели эффективности изначально отсутствуют в наборе данных, мы можем получить их с помощью ИИ, анализируя сами текстовые данные.
Когда категории отсортированы по степени важности, наиболее важные из них визуально очевидны. Часто бывает полезно пройтись по списку по порядку, устраняя проблемы, выявленные ИИ, в порядке их возникновения. Эта простая стратегия может оказать существенное влияние на ключевые показатели эффективности.
В одном случае компания-разработчик программного обеспечения хотела улучшить свою поддержку клиентов, но имела на руках только тысячи обращений в службу поддержки без какой-либо оценки качества. Мы использовали ИИ для оценки каждого обращения и формирования оценки качества поддержки.
Получив оценку качества, полученную с помощью ИИ, мы использовали таксономические категории в качестве предикторов, чтобы определить, какие темы разговоров связаны с низким качеством поддержки. Результаты оказались неожиданными. Компания предполагала, что сложные технические проблемы будут главной причиной низкого качества поддержки, однако на деле наиболее значимым предиктором низкого качества взаимодействия оказалась проблема «Смена пароля».
Основные факторы, влияющие на удовлетворенность клиентов.
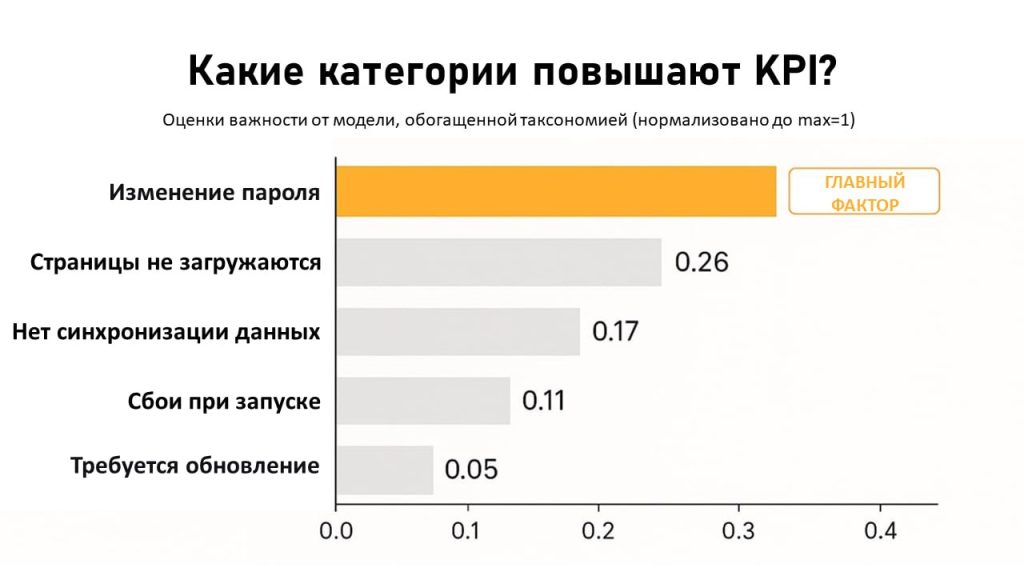
Анализ показал, что запросы на смену пароля заставляли клиентов подолгу находиться в режиме ожидания, многократно перенаправлялись между операторами и, как результат, вызывали серьезное недовольство клиентов. Компания обнаружила, что её система смены паролей была неисправна, из-за чего простые запросы становились неоправданно сложными. Но поскольку эти запросы казались «лёгкими», руководство никогда не обращало на них внимания.
По результатам применения технологии Таксономия «Точно в Срок», компания выявила и устранила основные системные проблемы и, в частности, оптимизировала процесс смены пароля. В результате устранения этой единственной проблемы общие показатели качества поддержки улучшились на 20%, а количество заявок, связанных со сменой пароля, сократилось на 60%. После устранения всех проблем качество поддержки повысилось на 40%.
Без выявления показателей качества и таксономического анализа, полученных с помощью ИИ, компания продолжала бы концентрироваться на сложных технических проблемах, в то время как легко устранимая неисправность со сменой пароля продолжала бы раздражать тысячи клиентов.
Когда нужна ТВС-таксономия?
Таксономии «Точно в Срок» заполняют пробел, который не могут заполнить специалисты по таксономии: если вам нужны аналитические показатели, основанные на оперативных данных, быстрее, чем их может предоставить аналитик, ТВС-таксономия – отличный вариант. Эта технология идеально подходит для анализа, который должен быть проведен в течение короткого времени, когда ожидание результатов ручной категоризации в течение нескольких недель означает полную утерю контроля над ситуацией. Но применение этой технологии выходит далеко за рамки простого ускорения анализа.
Таксономии ТВС особенно эффективны, когда вы исследуете неизведанные территории – выходите на новые рынки, запускаете инновационные продукты или исследуете незнакомые сегменты клиентов, где вы действительно не знаете, какие темы могут содержаться в данных. Традиционные таксономии требуют предварительного определения категорий, но иногда самые ценные идеи возникают из выявления закономерностей, которые вы никак не могли предвидеть. Это делает ТВС Таксономии бесценными для конкурентной разведки, выявления новых тенденций, или любой ситуации, когда вы пытаетесь понять, «что происходит на самом деле», а не подтвердить то, что уже подозреваете.
Они также идеально подходят для меняющихся потоков контента, где сама тематика постоянно меняется. Обсуждения в социальных сетях, постоянные отзывы клиентов, стенограммы чатов и пользовательский контент не остаются статичными – появляются новые темы, меняется язык, — и хорошо работавшая вчера таксономия может начать упускать из виду самые важные темы сегодняшнего дня. Таксономия ТВС адаптируется по мере этих изменений, что делает её прекрасным решением для мониторинга бренда, управления сообществами и других задач, где актуальность важнее, чем поддержание строгой согласованности.
Этот подход особенно эффективен для наборов данных среднего размера — обычно от нескольких тысяч до десятков тысяч документов. Он подходит для множества бизнес-сценариев: ежеквартального анализа обратной связи, рыночных исследований, оценки пилотных проектов или организации структуры данных в подразделениях. Это уже достаточно существенный объем данных, чтобы ручной анализ стал непрактичным, но при этом не критично большой, чтобы ИИ мог выявлять действительно значимые закономерности и не затеряться в зашумленности информации.
ТВС-Таксономии также отлично подходят для проверки концепций. Прежде чем приступить к крупному проекту по ручному построению таксономии, они могут быстро продемонстрировать что возможно получить из ваших конкретных данных. Это делает их бесценными для пилотных проектов, обоснования бюджета или просто для оценки эффективности текстового анализа в решении конкретной задачи. А когда ресурсы ограничены – будь то нехватка выделенного исследовательского персонала, сжатые сроки или ограниченный бюджет – они могут предоставить важную информацию, которая в противном случае потребовала бы недель ручной работы или дорогостоящих внешних консультаций.
Технология ТВС-Таксономии меньше подходит для построения крупных корпоративных таксономий, включающих тысяч предопределённых категорий, рассмотрения ситуаций, требующих строгого соответствия отраслевым стандартам или нормативным актам, а также для долгосрочных стратегических систем классификации, где согласованность на протяжении многих лет важнее скорости. Если вы интегрируетесь с существующими корпоративными системами или разрабатываете что-то, что должно соответствовать определённым юридическим или отраслевым требованиям, традиционные подходы будут более подходящими.
При этом многие организации не рассматривают это как выбор «или-или», а находят наибольшую ценность в гибридных подходах, где таксономии ТВС расширяют и улучшают традиционные структуры, созданные человеком. Представьте себе крупную компанию, которая потратила годы на разработку комплексной таксономии для анализа отзывов клиентов. У неё есть устоявшиеся категории верхнего уровня, такие как «Качество продукта», «Впечатления от обслуживания» и «Проблемы с выставлением счетов». Эти общие категории хорошо работают и согласуются с их структурами отчетности и бизнес-процессами.
Однако на более детальном уровне их традиционная таксономия может относить всё к категории «Качество продукции», не отражая специфических нюансов, выявляемых в реальных отзывах клиентов. Именно здесь таксономия ТВС могут оказаться незаменима. Запущенная специально на отзывах, уже отнесённых к категории «Качество продукции», она может автоматически выявлять детальные подкатегории, отражающие темы, которые реально волнуют клиентов: «Повреждение упаковки», «Инструкции по сборке», «Точность цветопередачи», «Надежность работы системы спустя 6 месяцев» и десятки других конкретных проблем, которые специалисты по таксономии могли не предвидеть или не придать им приоритетного значения.
Такие расширения категорий существующей таксономии, созданные ИИ, дают дополнительную важную информацию конечным пользователям, предоставляя им мгновенный доступ к подробной категоризации. При этом общая корпоративная таксономия остаётся стабильной и соответствующей всем нормативным требованиям. В качестве альтернативы, результаты ТВС могут служить ориентиром для специалистов-таксономистов, подсказывая им, где их существующих категорий недостаточно и какие новые подкатегории позволят отразить наиболее значимые различия в данных. Вместо того, чтобы гадать, какие подробные категории добавить, они могут эмпирически увидеть, какие новые темы появляются — и насколько часто.
Такой подход позволяет организации объединить лучшее из обоих миров: управляемость и последовательность традиционных таксономий на стратегическом уровне в сочетании с оперативностью и точностью данных таксономий ТВС, где детальная категоризация имеет наибольшее значение.
Заключение: будущее организации данных
Таксономии «Точно в Срок» представляют собой фундаментальный сдвиг в нашем подходе к анализу неструктурированных данных. Вместо того, чтобы пытаться поместить данные в заранее определённые категории или неделями ждать результатов ручного анализа, Таксономия «Точно в Срок» позволяет данным раскрыть свою собственную структуру и дает вам возможность немедленно начать извлекать ценную информацию.
Эта технология работает, потому что она отражает то, как на самом деле думают эксперты-люди о категоризации: выявляя закономерности, группируя схожие концепции и углубляя понимание по мере поступления новой информации. Но она делает это с машинной скоростью и в больших масштабах, обрабатывая тысячи документов за время, которое человеку потребовалось бы для прочтения десятков.
Независимо от того, что именно вы делаете – выпускаете на рынок новый продукт, анализируете результаты опросов, ведете мониторинг данных социальных сетей или пытаетесь выявить проблемы в работе службы поддержки клиентов – основная задача остаётся неизменной: преобразование неструктурированного текста в полезную для дальнейшего анализа и принятия решений структурированную информацию. Таксономии «Точно в Срок» меняют правила игры: они делают это преобразование мгновенным – вместо запоздалого, всеобъемлющим – вместо выборочного, и адаптивным – вместо статичного.
Вопрос не в том, изменит ли ИИ то, как мы организуем и анализируем текстовые данные – он уже это сделал. Вопрос в том, сумеете ли вы воспользоваться этими новыми технологическими возможностями для оперативного и детального структурирования текстовых данных, или предпочтете продолжать ждать идеальных таксономий, которые часто появляются слишком поздно для принятия своевременных решений.
ДРУГИЕ НОВОСТИ И СТАТЬИ

Интервью с Сергеем Ананяном в преддверии конференции «Генеративный искусственный интеллект в отраслях экономики и социальной сфере»
Интервью Сергея Ананяна в преддверии конференции «Генеративный искусственный интеллект в отраслях экономики и социальной сфере: Pro&Contra 2025». Оригинал интервью размещен...
Читать далее
Текстовый анализ для работы с Excel: как легко превратить «сырые» таблицы в чистые данные
Текстовый анализ для работы с Excel: как легко превратить «сырые» таблицы в чистые данные Каждый, кто работает с данными, знает...
Читать далее