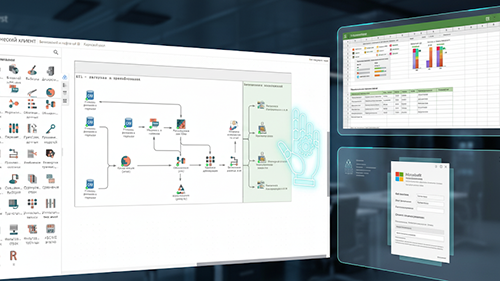
Автоматизация регламентной отчетности: экспорт данных из PolyAnalyst в шаблоны Excel и Word Системы PolyAnalyst и PolyAnalyst Grid предоставляют мощные инструменты...
Читать далее

Интервью с Сергеем Ананяном в преддверии конференции «Генеративный искусственный интеллект в отраслях экономики и социальной сфере»
Интервью Сергея Ананяна в преддверии конференции «Генеративный искусственный интеллект в отраслях экономики и социальной сфере: Pro&Contra 2025». Оригинал интервью размещен...
Читать далее
Текстовый анализ для работы с Excel: как легко превратить «сырые» таблицы в чистые данные
Текстовый анализ для работы с Excel: как легко превратить «сырые» таблицы в чистые данные Каждый, кто работает с данными, знает...
Читать далее